Appendix I — Getting Started with SPSS
Installation, Interface, and Basic Workflows
I.1 Purpose & Outcomes
This chapter orients you to SPSS 31 fundamentals. By the end, you will be able to navigate the SPSS interface including the Data Editor, Variable View, Output Viewer, and Syntax Editor. You will learn to set up organized project folders and create reproducible workflows. The chapter covers how to import and enter data with proper metadata, perform basic transformations such as computing new variables and recoding values, and build and export professional charts. You will also learn to run and annotate syntax scripts, conduct essential data integrity checks, and export APA-ready tables and figures for your assignments and research papers.
I.2 Why This Matters
This chapter establishes foundational practices for data management and reproducibility that form the backbone of professional statistical work. The habits you develop here—organizing files systematically, documenting your work, maintaining clean data, and creating reproducible workflows—will serve you throughout your academic career and beyond, regardless of your field or the scale of your projects.
I.2.1 Platforms
SPSS 31 is available for both Windows and macOS. When installing on Windows, run the installer executable and follow the installation wizard, ensuring you have administrator privileges if required. On macOS, follow the standard installation steps and confirm that your system architecture is compatible (Intel or Apple Silicon). On first launch, regardless of platform, you may need to grant necessary permissions for the application to access your files. The license verification screen will appear on the splash screen when you open SPSS for the first time.
SPSS uses either a site license (common for universities) or an individual authorization code. You’ll configure the license manager during initial setup. Be aware of offline grace periods if you need to work without internet access, and understand the renewal process for your institution’s license.
I.2.2 Updates & Folders
You can check for software patches and updates by going to Help > Check for Updates in the menu bar. SPSS stores default user files in locations like Documents/SPSS or similar folders on your system. Understanding where templates and output files are saved will help you locate your work quickly.
I.3 Project Organization
Good file organization is fundamental to successful data analysis. Start by creating a dedicated project folder where you can store all your work in one place. Within this main folder, create subfolders to organize your materials logically: one for raw data files, one for syntax scripts, one for output files, and one for figures and results. This structure makes it easy to locate files months later and simplifies sharing your work with collaborators. Use descriptive file names that clearly indicate content and version—for example, analysis_main.sps for your primary syntax file or results_v02_final.spv for saved output. Include dates in filenames when tracking iterations: data_cleaned_20250110.sav. Establish a consistent naming convention and stick to it throughout your project. Finally, save your work frequently to prevent data loss from unexpected software crashes or computer failures.
I.4 SPSS Interface Tour
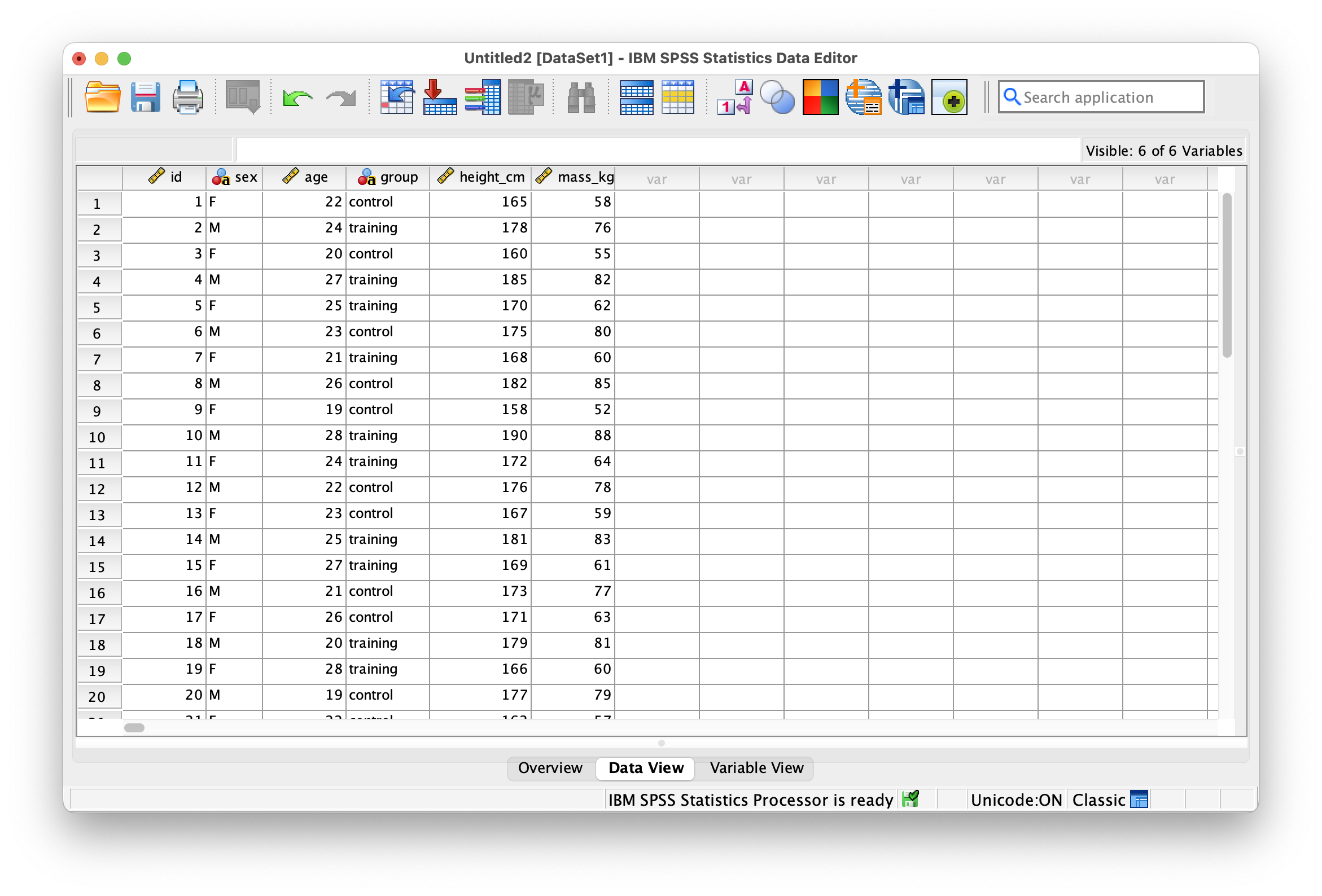
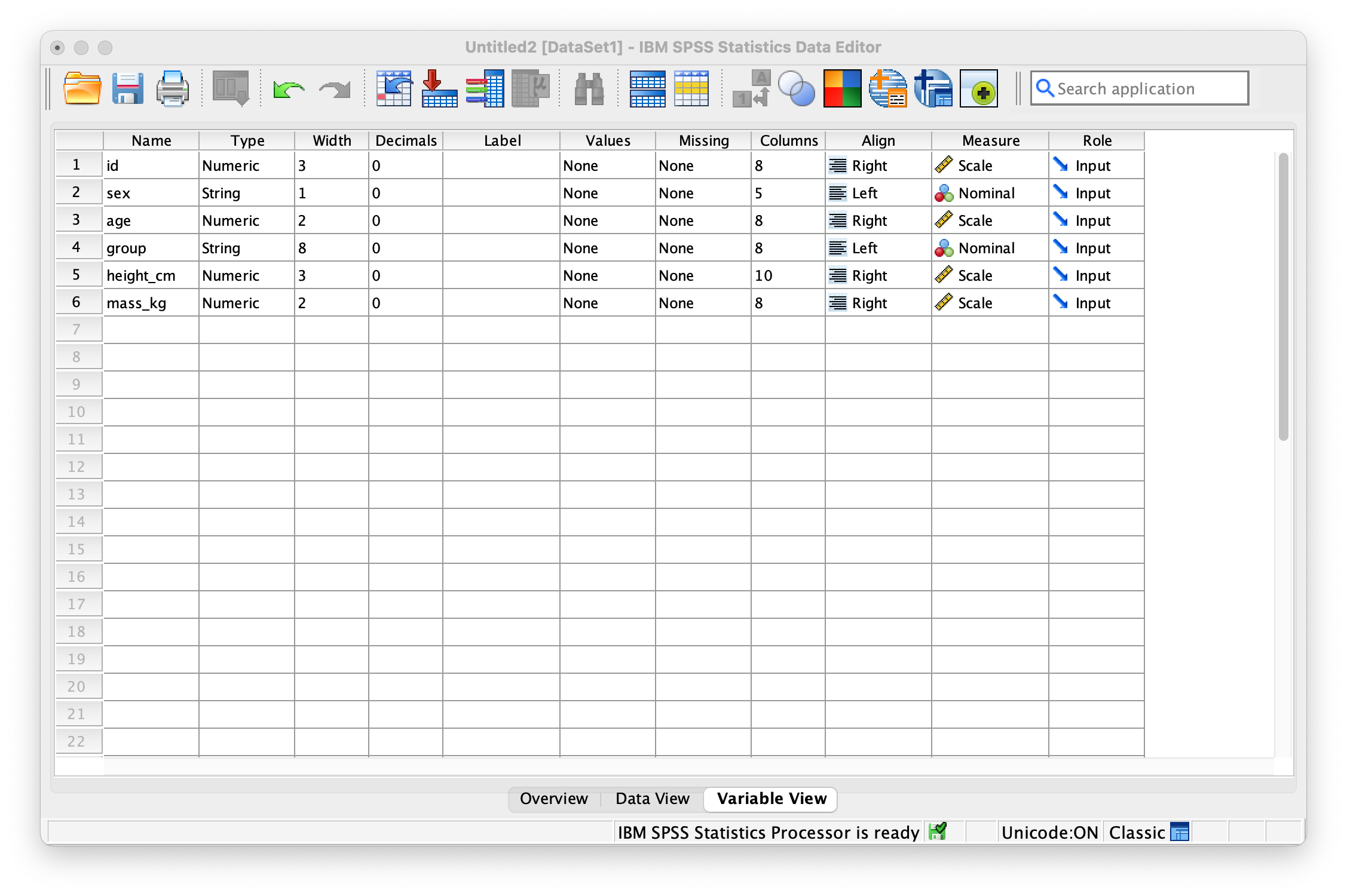
The Data Editor has two main views that you’ll switch between frequently. Data View shows your actual data arranged in rows and columns, where each row represents a case (like a participant) and each column represents a variable (like age or test score). Variable View displays the metadata for each variable, allowing you to define properties like variable type, labels, and missing values.
I.4.1 Chart Builder
The Chart Builder uses an intuitive drag-and-drop interface that makes creating visualizations straightforward. You can preview how your chart will look and customize various elements like colors, labels, and formatting before generating the final version. While SPSS also maintains Legacy Dialogs for creating charts (found under Graphs > Legacy Dialogs), the Chart Builder offers a more visual and user-friendly approach with better preview capabilities. The legacy dialogs are still available for users who prefer the older interface or need specific chart types not yet available in Chart Builder, but for most purposes, Chart Builder provides greater flexibility and easier customization.
I.5 Datasets & File Types
SPSS works with native .sav/.zsav files and imports .csv, .xlsx, and .txt. Output is saved as .spv and can be exported to common formats like .pdf, .docx, .png, and .html.
I.6 Data Entry & Variable View
Use Variable View to define types, labels, and missing codes. Data View shows cases and variables; switch between them as you edit and review your dataset.
I.7 Opening vs. Importing Data
SPSS distinguishes between opening data files and importing data files, and understanding this difference is important for working efficiently.
I.7.1 Opening Data Files
Use File > Open > Data when working with files that are already in SPSS format (.sav or .zsav) or when opening simple data files like CSV where SPSS can automatically handle the conversion. When you open a CSV file this way, SPSS recognizes the file format and launches the Text Import Wizard to help you configure how the data should be read. This is the most common approach for everyday data work.
I.7.2 Importing Data Files
Use File > Import Data when you need more control over how data from other formats (Excel, databases, text files with complex structures) are brought into SPSS. The Import Data menu provides specialized wizards for different file types:
- Excel: Handles
.xlsxand.xlsfiles with multiple worksheets - Text Data: For delimited or fixed-width text files requiring specific configuration
- Database: Connects to external databases like SQL Server or Oracle
- Other formats: SAS, Stata, and other statistical software formats
The key distinction: Open is simpler and works for most common situations, while Import offers specialized tools for complex data sources.
I.8 Working with CSV Files
I.8.1 CSV Import Steps
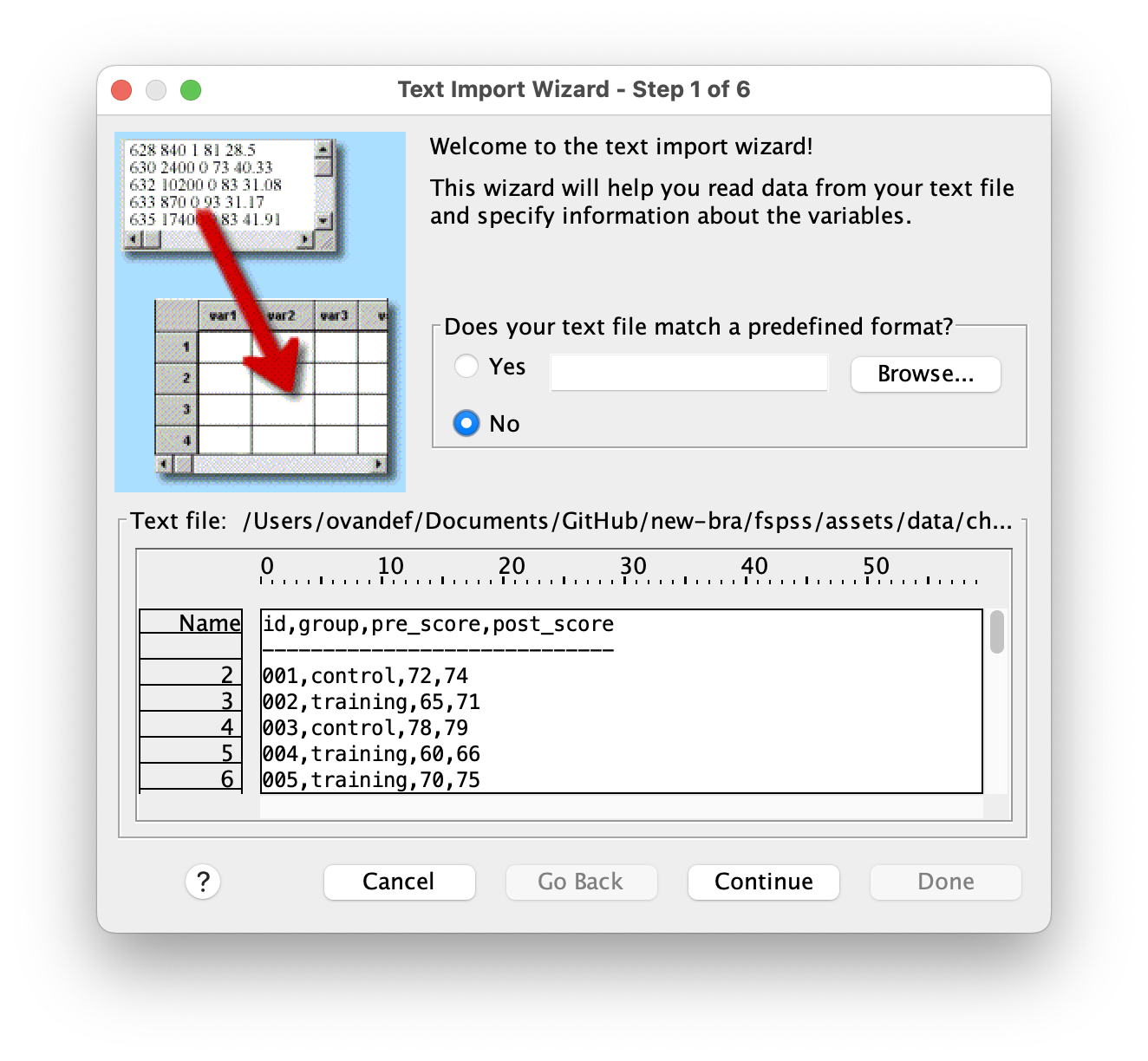
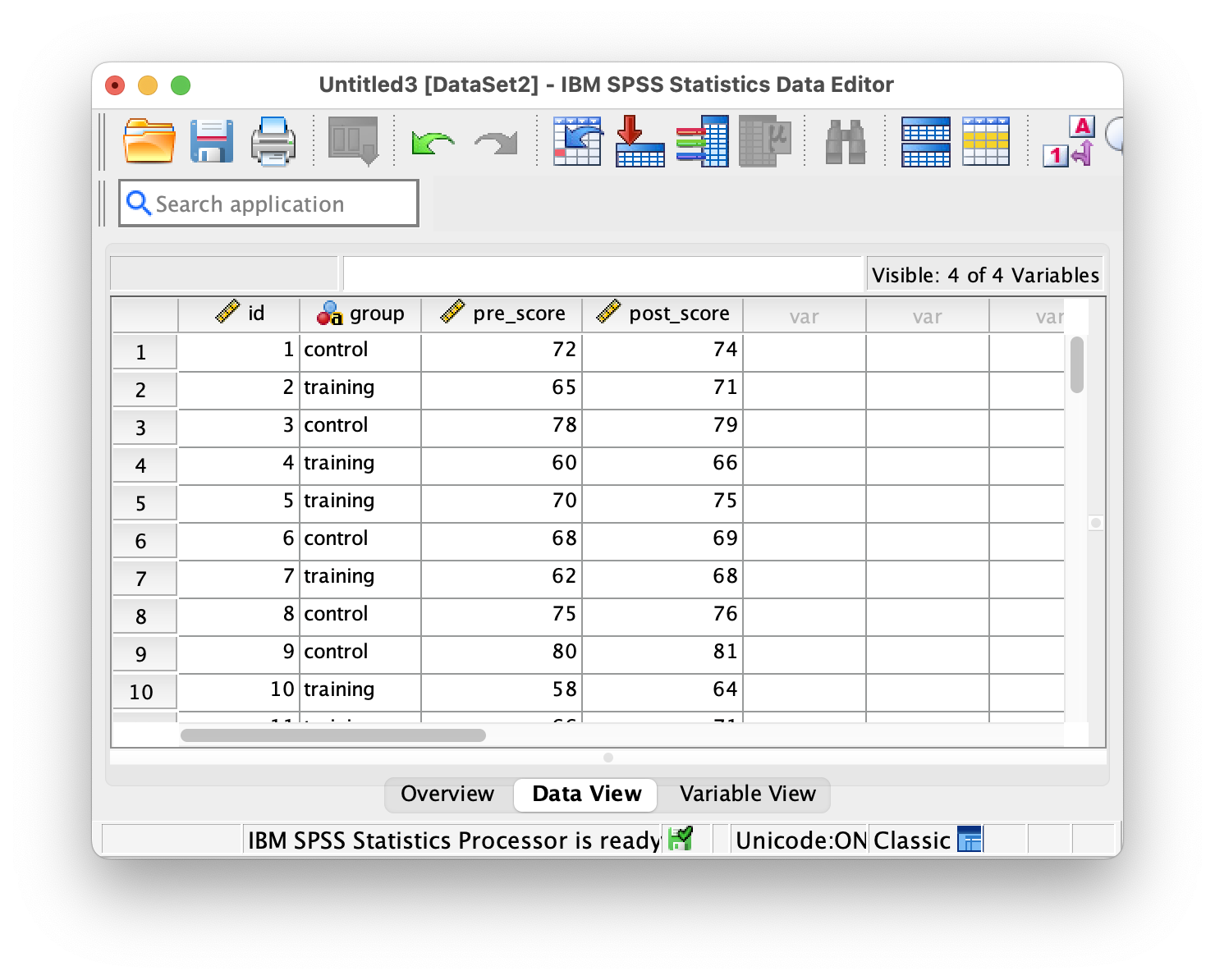
To open a CSV file, go to File > Open > Data and browse to your CSV file. SPSS automatically recognizes CSV files and launches the Text Import Wizard. The wizard asks you to select the delimiter that separates values in your file—usually this is a comma, but it could be a tab, semicolon, or other character. Make sure to specify that the first row contains variable names so SPSS uses those as column headers. Take time to preview the data and confirm that SPSS has correctly identified each variable’s data type (numeric, string, etc.). Once everything looks correct, save your imported data as a .sav or .zsav file so you have a native SPSS version to work with.
I.9 Working with Excel Files
I.9.1 Excel Import
For Excel files, use File > Import Data > Excel to start the import wizard. You’ll need to select which worksheet contains your data if the Excel file has multiple sheets. The wizard allows you to specify the range of cells to import and whether the first row contains variable names. Pay special attention to columns that might contain mixed types of data (both numbers and text), as these can cause import problems if not handled correctly. Excel files with complex formatting, merged cells, or formulas may require cleanup before importing.
I.9.2 Define Variable Properties
After importing data from any source, SPSS offers a helpful tool at Data > Define Variable Properties that can save you time. This feature scans through your data values and suggests appropriate variable types, labels, and missing value codes based on what it finds. Review these suggestions carefully and apply the ones that make sense for your dataset.
I.10 Sample Datasets
You can download the practice datasets directly below:
- athletes.csv — Instructor demonstration file
- Download: athletes.csv
- Variables: id, sex, age, group, height_cm, mass_kg, pre_score, post_score
- 20 cases; includes pre/post scores for transformation demos
- participants.csv — Demographics and anthropometric data
- Download: participants.csv
- Variables: id, sex, age, group, height_cm, mass_kg
- 24 cases; balanced groups
- pre_post_scores.csv — Pre/post intervention scores
- Download: pre_post_scores.csv
- Variables: id, group, pre_score, post_score
- 26 cases; includes missing values for practice
- reaction_time_trials.csv — Repeated measures reaction times
- Download: reaction_time_trials.csv
- Variables: id, condition, rt_t1_ms, rt_t2_ms, rt_t3_ms
- 20 cases; wide format for within-subjects analysis
I.11 Saving & Exporting
I.11.1 Save Dataset
Once you’ve organized your data and performed initial transformations, it’s important to save your work in SPSS’s native format. Navigate to File > Save As and choose between .sav (standard SPSS file) and .zsav (compressed format that takes less disk space). Use descriptive filenames that include version information, such as participants_v01_cleaned.sav or study_data_20250110.sav, so you can track different iterations of your dataset as you work through analyses.
I.11.2 Export Output
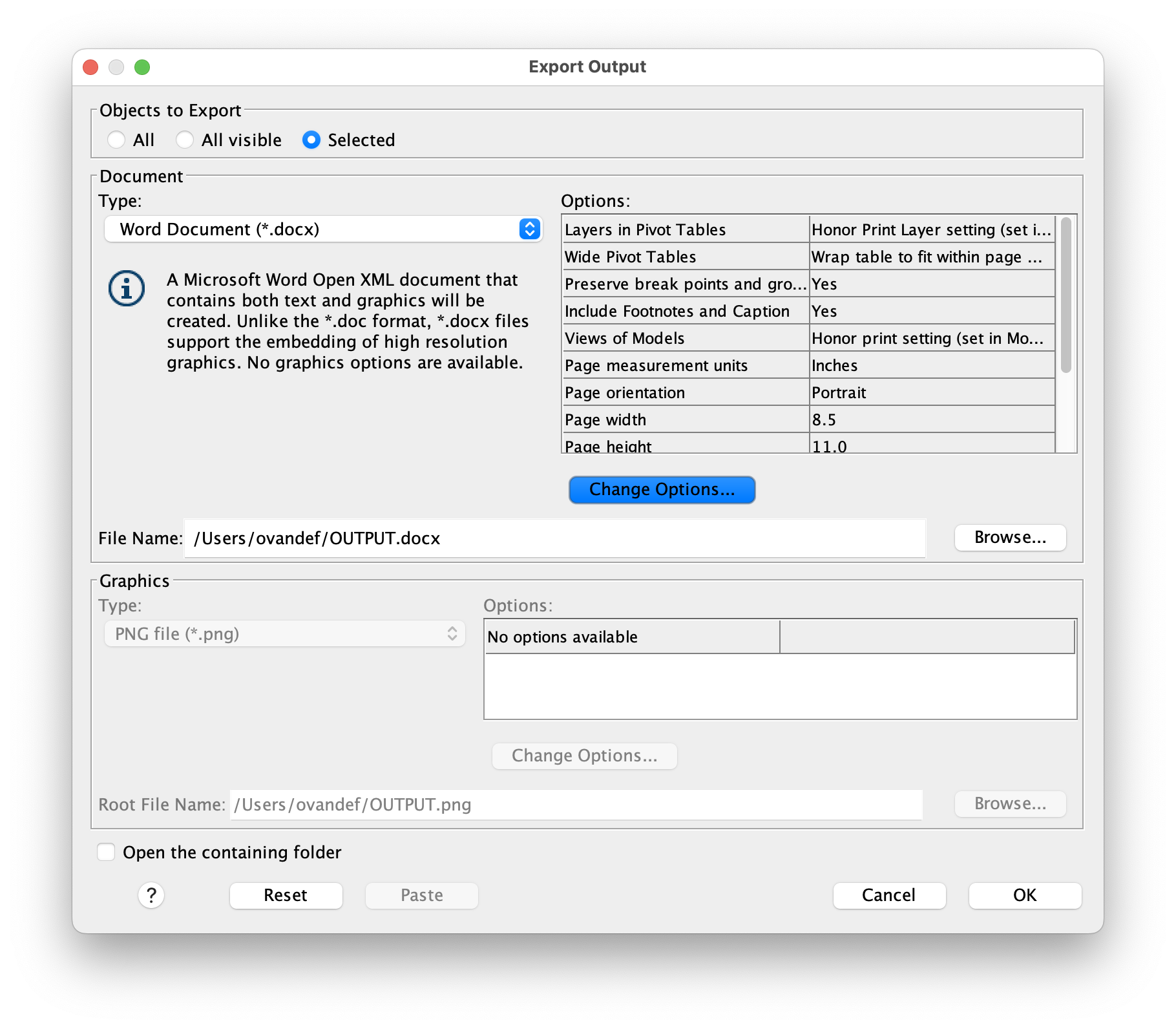
When you’re ready to share results or include them in papers and assignments, SPSS makes it easy to export your work in multiple formats. For statistical tables and summary statistics, use File > Export and select Word, PDF, or Excel format depending on your needs. For charts and figures, right-click directly on the chart in the Output Viewer and choose Export; PNG format is recommended for print publications and presentations because it maintains high quality at various sizes.
I.11.3 APA Basics
Whether you’re creating tables for a paper or assignment, follow these APA formatting conventions to ensure professional appearance. Place table titles above the table (centered and bold) and any explanatory notes below in smaller text. Keep numerical values consistent by rounding to 2 decimal places throughout your table—this creates visual consistency and makes patterns easier to spot. Use clear, descriptive variable labels rather than cryptic abbreviations, and avoid unnecessary visual elements like gridlines, excessive colors, or 3D effects that distract from the data itself.
I.12 Chart Builder Primer
SPSS’s Chart Builder provides an intuitive, drag-and-drop interface for creating professional visualizations. Rather than memorizing specific menu paths for each type of chart, you can experiment with different chart types and see previews in real time. This visual approach helps you choose the most appropriate visualization for your data and makes it easy to modify charts after they’re created.
I.12.1 Common Chart Types
Different chart types serve different purposes depending on your data and what you want to communicate. Use a Histogram when you want to visualize the distribution of a single continuous variable—it shows you whether your data is normally distributed or skewed. A Boxplot is excellent for comparing distributions across groups; it displays the median, quartiles, and outliers all in one compact graphic. Bar Charts are useful for showing counts or mean values broken down by categories, making it easy to compare groups at a glance. A Scatterplot is the standard choice when you want to show the relationship between two continuous variables and help readers see patterns or correlations.
I.12.2 Steps
To create any chart, start by selecting Graphs > Chart Builder from the menu. You’ll see a gallery of chart types on the left; drag your chosen chart type onto the canvas in the center. Assign your variables to the appropriate axes by dragging them from the Variables list. Once the basic structure is in place, customize the appearance by adding titles, axis labels, changing colors, and adjusting fonts to match your preferences. Finally, click OK to generate the chart in the Output Viewer, where you can further refine it if needed.
Further reading: To learn more about effective data visualization, click here
I.13 Basic Transformations
I.13.1 Compute Variable
Often you need to create new variables based on calculations involving existing ones. SPSS’s Compute Variable feature lets you define mathematical expressions that transform your data. Access it through Transform > Compute Variable, where you can build new variables from existing ones. Common uses include creating z-scores (standardized values for comparison across variables), calculating difference or change scores (useful for pre-post designs), or summing items into composite scales. Once you define your expression, SPSS applies it to all cases in your dataset, creating a new column with the computed values.
* Compute z-score.
COMPUTE z_mass = (mass_kg - 75) / 12.
EXECUTE.
* Compute change score.
COMPUTE change = post_score - pre_score.
EXECUTE.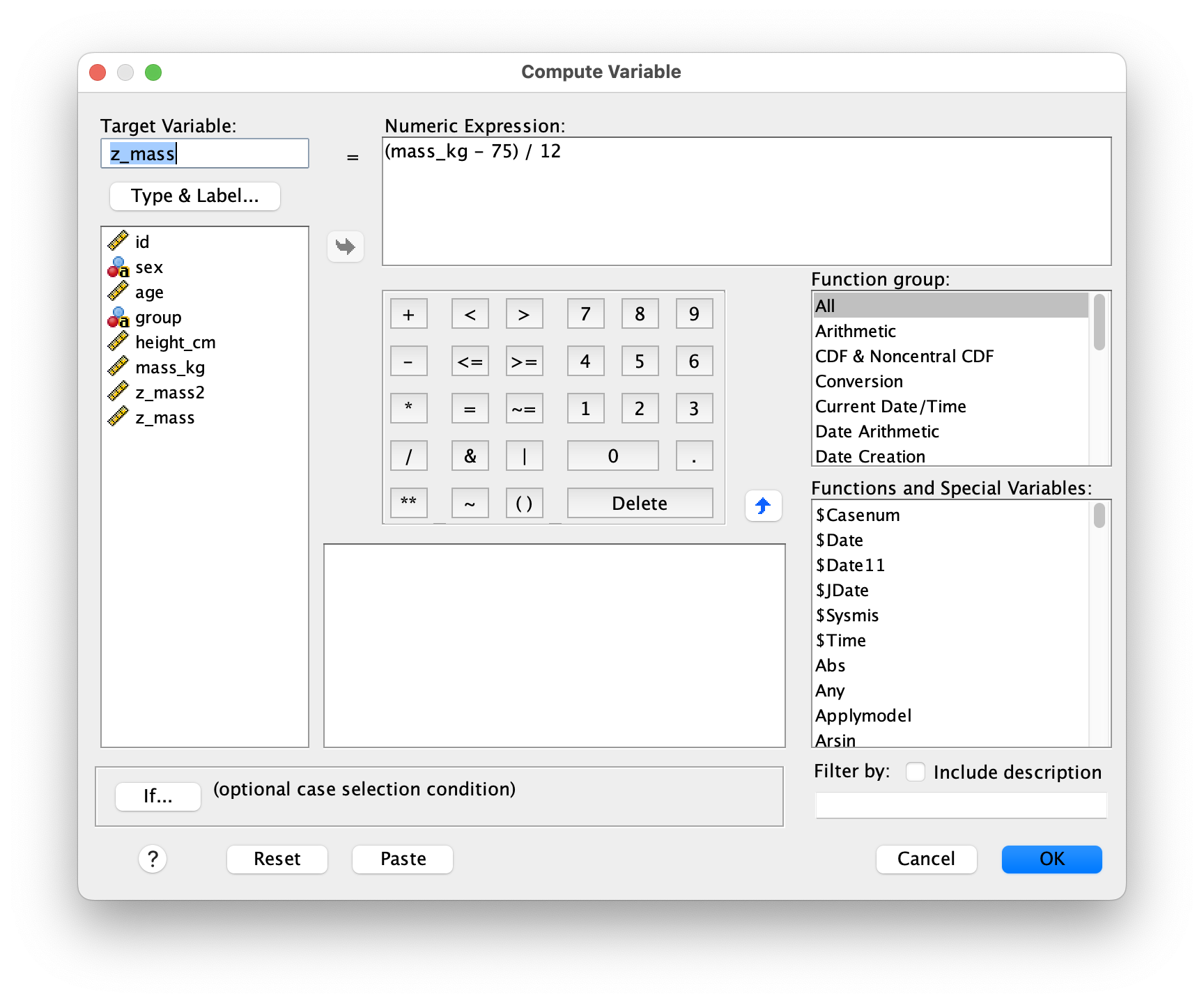
I.13.2 Recode Into Different Variables
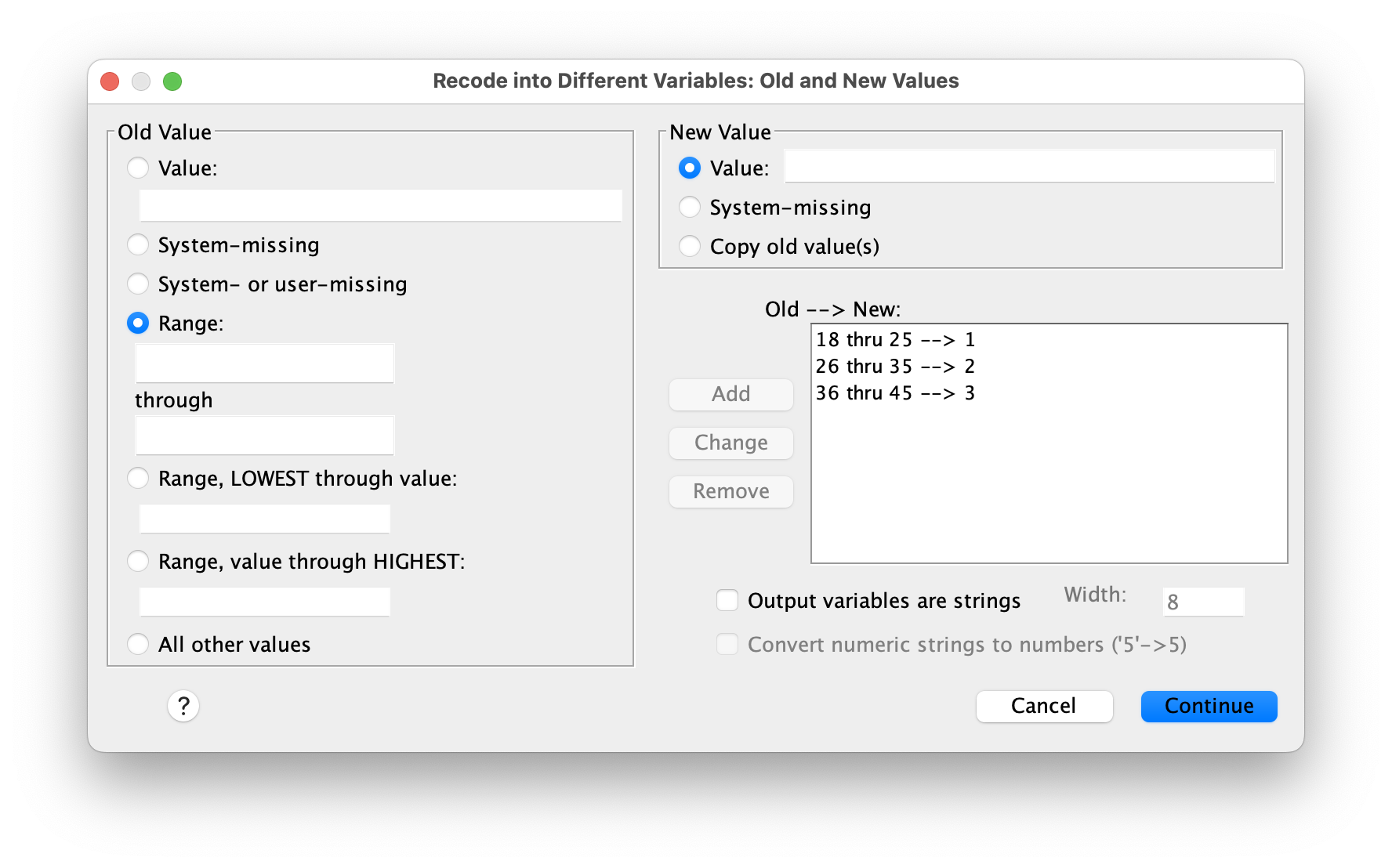
Recoding allows you to group continuous values into categories or change coding schemes while preserving your original data intact. Use Transform > Recode into Different Variables to specify how old values should map to new values. For example, you might recode age into age groups (18-25, 26-35, etc.) or recode a 5-point Likert scale into broader categories. Because you’re recoding “into different variables,” your original variable remains unchanged—SPSS creates a new variable with the recoded values, which is safer than overwriting your raw data.
* Recode age into groups.
RECODE age (18 thru 25=1) (26 thru 35=2) (36 thru 45=3) INTO age_group.
VALUE LABELS age_group 1 '18-25' 2 '26-35' 3 '36-45'.
EXECUTE.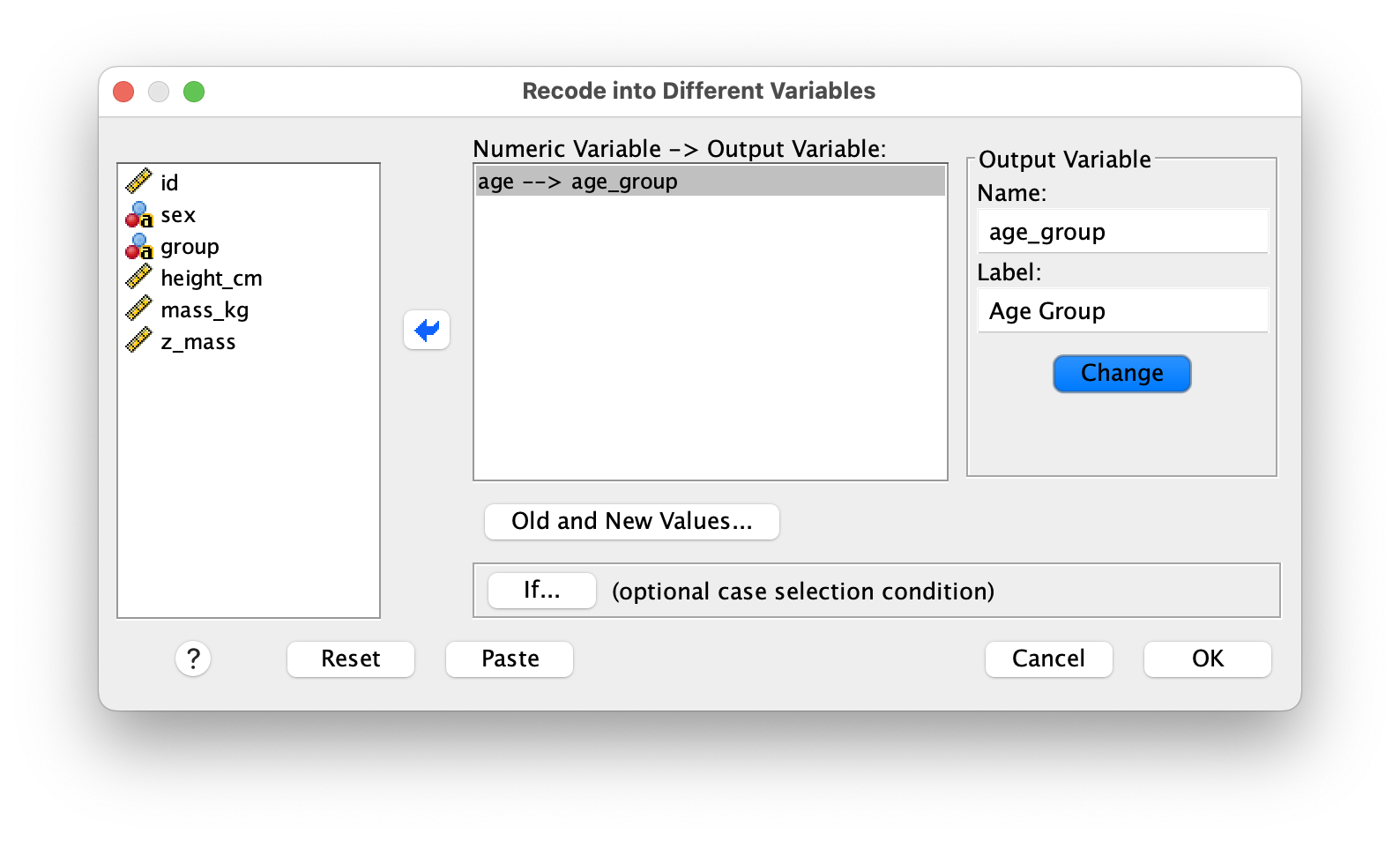
I.13.3 Reverse-Scoring
When creating composite scales from multiple items, you sometimes encounter items that are worded in the opposite direction—these need to be reverse-scored so that all items measure the construct in the same direction. For example, if your scale ranges from 1 to 5, reverse scoring an item means subtracting its value from 6 (one point higher than your maximum). This flips the scale so that a 1 becomes a 5 and vice versa. Always create a new variable with the reverse-scored values rather than overwriting the original item, so you maintain a record of your raw data. You can accomplish this with a simple Compute Variable expression:
* Reverse score (assuming 1-5 scale).
COMPUTE item1_rev = 6 - item1.
EXECUTE.I.14 Syntax Basics
While SPSS’s menu-driven interface is user-friendly, syntax—the command language underlying SPSS—is essential for serious data analysis. Learning syntax might seem intimidating at first, but it offers powerful advantages that make your work more professional and reliable.
I.14.1 Why Use Syntax?
Syntax creates a permanent record of every step you took, allowing you to reproduce your exact analyses weeks or months later—critical when you need to verify results or make small adjustments to your work. You can also document your thinking by adding comments throughout your syntax file, explaining why you chose specific approaches or noting data issues you discovered. Beyond reproducibility, syntax lets you batch process multiple operations at once, saving time when you have repetitive tasks or need to apply the same transformations to multiple variables.
I.14.2 Creating Syntax
There are several ways to build a syntax file. The easiest approach for beginners is to use the menu system as you normally would, but instead of clicking OK to execute the command, click Paste. This copies the equivalent syntax command to a syntax editor window, where you can review, modify, and save it. As you become more comfortable with syntax, you can also type commands directly into the Syntax Editor, and many experienced users find this faster than navigating menus. Always save your syntax files with a .sps extension so they’re easy to identify and can be opened reliably on any system.
I.14.3 Running Syntax
To run your syntax commands, highlight the lines you want to execute (or leave everything highlighted to run the entire file), then click the Run button (green arrow) in the toolbar or use the keyboard shortcut Cmd+R on Mac or Ctrl+R on Windows. SPSS will process your commands in order and generate output in the Output Viewer. An important note: after any commands that modify your data (like Compute, Recode, or Select If), include the EXECUTE. statement to tell SPSS to finalize the changes before moving to the next step. Some users add EXECUTE. at the end of every section for extra clarity.
* Load dataset.
GET FILE='assets/data/ch01/participants.sav'.
DATASET NAME participants.
* Descriptive statistics.
DESCRIPTIVES VARIABLES=height_cm mass_kg
/STATISTICS=MEAN STDDEV MIN MAX.
EXECUTE.I.14.4 Annotation
Good comments are invaluable when you return to your syntax weeks later or when a colleague needs to understand your work. Use a single asterisk * at the beginning of a line for single-line comments (SPSS will ignore everything from the asterisk to the period). For longer explanations that span multiple lines, use /* */ to wrap your comment. At the very top of your syntax file, always include a header documenting the purpose of the analysis, the date it was created or last modified, and who wrote it. These simple practices make your work look professional and help prevent confusion or mistakes when revisiting old analyses.
I.15 Data Integrity Checks
Before you begin any analysis, it’s essential to verify that your data has been entered and imported correctly. Data integrity checks help you catch errors early—before they compromise your results. These checks typically look for out-of-range values, suspicious patterns, and missing data issues.
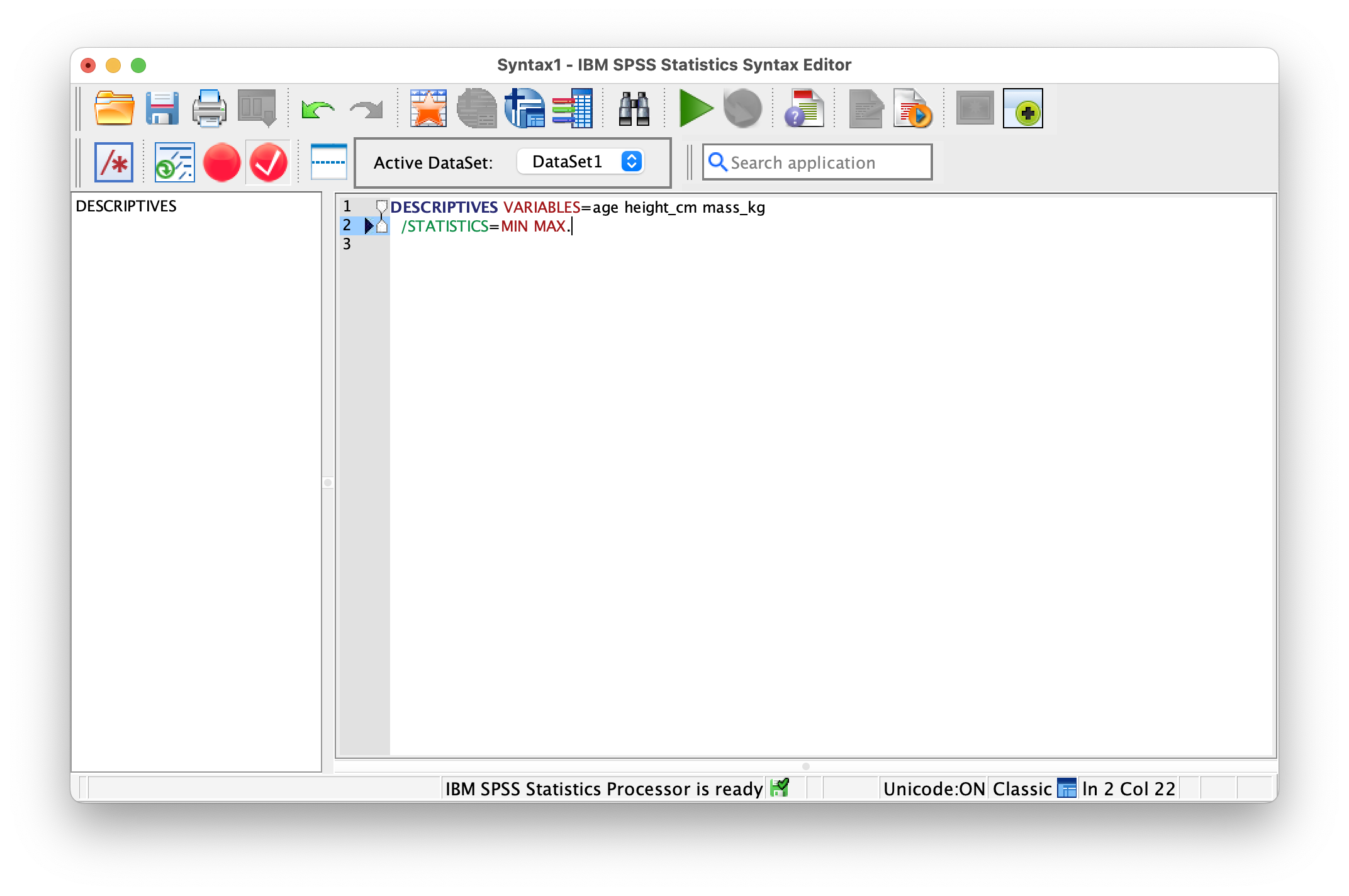
I.15.1 Check Ranges
Run a simple Descriptive Statistics command to see the minimum and maximum values for your numeric variables. This is your first line of defense against data entry errors. Look carefully at these values—if someone entered a height of 999 cm or an age of -5, these errors will be obvious:
DESCRIPTIVES VARIABLES=age height_cm mass_kg
/STATISTICS=MIN MAX.Any impossible values should be investigated. They might be legitimate outliers, data entry errors, or missing value codes that weren’t properly configured.
I.15.2 Missing Data Patterns
Understanding patterns of missing data is crucial because they can affect your analyses in subtle ways. Use the Frequencies command to examine which cases have missing values and whether the missingness follows any pattern:
FREQUENCIES VARIABLES=pre_score post_score
/FORMAT=NOTABLE
/STATISTICS=MISSING.For example, if all missing values in a post_score variable come from one group, that suggests a systematic problem rather than random missing data. This information will help you decide whether to use listwise deletion, imputation, or other strategies for handling missing values.
I.15.3 Identify Duplicates
Occasionally you may have duplicate rows in your dataset—cases that were entered twice by mistake. SPSS provides a tool at Data > Identify Duplicate Cases that scans your data and highlights potential duplicates. Specify your ID variable so SPSS knows how to match cases, and it will flag duplicates for your review. You then decide whether to keep the first occurrence, the last occurrence, or review each duplicate manually to determine which version is correct. This step is particularly important if you’ve merged multiple data sources.
I.15.4 Sort and Select Cases
As you work with your data, you may want to organize it by certain variables or focus on a subset of cases. Use the Sort Cases command to arrange your data in a specific order, which is helpful for spotting patterns or preparing data for specific analyses. When you only want to analyze a portion of your data (for example, just the training group), use Select If to temporarily filter the dataset:
* Sort by ID.
SORT CASES BY id.
* Select cases for analysis.
SELECT IF (group = 'training').
EXECUTE.Note that Select If doesn’t delete cases—it just marks them as excluded from analyses. You can always clear the selection later to work with the full dataset again.
I.16 Preferences & Defaults
SPSS offers extensive customization options to tailor the interface and output to your preferences and workflow. Taking time to configure these settings will save you effort throughout the course.
I.16.1 Display Options
Navigate to Edit > Options > Output to control how SPSS displays your results. You can choose whether tables show variable names (compact but cryptic) or variable labels (more readable if you’ve entered descriptive labels). Set your default number of decimal places displayed—this affects readability and follows conventions (typically 2 decimals for most statistical output). You can also adjust the scientific notation threshold, which determines when SPSS switches to exponential notation for very large or very small numbers.
I.16.2 File Paths
Use Edit > Options to set your default locations for opening and saving files. This saves you from repeatedly navigating to the same folder. In your syntax files, use relative paths (like assets/data/ch01/participants.sav) rather than absolute paths (like /Users/yourname/Documents/...). Relative paths are portable—if you move your project folder to a different location or share it with someone else, the syntax will still work.
I.16.3 Output Style
Edit > Options > Pivot Tables lets you customize how tables appear in your output. SPSS includes an APA style option that automatically formats tables according to American Psychological Association standards—this is ideal for coursework and research papers. You can also adjust fonts and cell formatting to suit your preferences or match a specific publication style.
I.17 Quick Practice Tasks
These hands-on exercises will help you apply the concepts covered in this chapter. Work through each task systematically, documenting your steps as you go. These tasks build on each other, so complete them in order.
- Project Setup with Google Drive: Create a well-organized folder structure in your Google Drive to maintain all course materials in one centralized, accessible location. In your Google Drive, create a main folder called
SPSS_Course(or similar). Inside this main folder, create four subfolders:data(for raw and processed data files),syntax(for your .sps script files),output(for saved SPSS output files), andfigures(for exported charts and graphs).
Install Google Drive for Desktop on your computer so these folders sync automatically and appear as a regular folder on your Mac/PC. Once synced, you can access these folders through Finder (Mac) or File Explorer (Windows) just like any other local folder. In SPSS, this synced folder by going to File > Change Working Directory, thenset your working directory to point to this synced folder by going to File > Change Working Directory and navigating to the Google Drive folder on your computer. This setup ensures your work is automatically backed up to the cloud and accessible from any device.
Data Import and Initial Inspection: Download the
athletes.csvfile provided above and save it to yourdatasubfolder within your Google Drive SPSS_Course folder. Open SPSS and import this file using File > Open > Data, selecting the CSV format. After importing, examine the Data View to ensure all variables loaded correctly. Check that numeric variables appear as numbers (not text) and that there are no obvious formatting issues. Save the file asathletes.savin yourdatafolder.Configure Metadata: Switch to Variable View and systematically define metadata for all variables. Add meaningful variable labels that describe what each variable measures (e.g., “Athlete height in centimeters” for
height_cm, “Pre-test score” forpre_score, “Post-test score” forpost_score). For categorical variables likesexandgroup, define value labels (M = ‘Male’, F = ‘Female’ for sex; control = ‘Control’, training = ‘Training’ for group). Set the appropriate measurement level for each variable: Scale for continuous variables, Ordinal for ordered categories, and Nominal for unordered categories.Data Transformation: Create two new computed variables. First, create
bmifrom height and mass using the formula: BMI = mass_kg / (height_cm/100)². Second, create achange_scorevariable by subtracting pre_score from post_score to see training improvements. Use Transform > Compute Variable for both. Then, use Transform > Recode into Different Variables to create age groups from the continuousagevariable. Create categories: 18-25, 26-35, 36-45, 46+. Remember to add value labels to your newage_groupvariable.Visual Data Exploration: Open the Chart Builder (Graphs > Chart Builder) and create two visualizations. First, create a histogram of the
mass_kgvariable to examine its distribution—look for whether it appears normally distributed or skewed. Second, create a boxplot comparingmass_kgacross thegroupvariable to see if there are differences between control and training groups. Export both charts as image files to yourfiguresfolder using File > Export after right-clicking each chart.Syntax Documentation: This is crucial for reproducibility. Open a new Syntax Editor (File > New > Syntax). Go back through each of the steps above (import, compute, recode, chart) and use the Paste button instead of OK to capture the syntax for each operation. Organize your syntax file with clear comments explaining each section. Add
EXECUTE.commands after data transformations. Save this file aschapter01_practice.spsin yoursyntaxfolder. Close your dataset without saving, then run your entire syntax file from start to finish to verify it reproduces all your work.Data Quality Control: Run comprehensive data integrity checks. Use Descriptive Statistics to examine the minimum and maximum values for
age,height_cm, andmass_kg—verify that all values fall within plausible ranges (e.g., height between 140-210 cm). Use Frequencies to check for missing data patterns. Finally, use Data > Identify Duplicate Cases with theidvariable to ensure no participants were entered twice. Document any issues you find and how you resolved them.
I.18 Common Pitfalls
- Type Mismatches: Numbers imported as strings → failed analyses
- Missing Handling: Treating user-missing as valid; unintended listwise deletion
- Value Labels: Misaligned codes and labels; inconsistent order
- Paths: Hard-coded absolute paths break when project moves
- Overwriting: Recode into same variable without backup
- Manual Edits: Changing output tables without updating dataset or syntax
I.19 Readiness Checklist
I.20 Using SPSS 31 in Apporto
I.20.1 What is Apporto?
Apporto is a cloud-based virtual desktop platform that provides access to software applications through your web browser. For this course, you’ll use Apporto to run SPSS 31 without needing to install it on your personal computer. This ensures everyone has access to the same version of SPSS regardless of their device (Windows, Mac, Chromebook, etc.).
I.20.2 Accessing Apporto
- Open your web browser and navigate to the Apporto login page link provided in Canvas
- Log in using your institutional credentials
- Once logged in, you’ll see a virtual desktop environment
I.20.3 Launching SPSS 31
- On the Apporto desktop, look for the SPSS icon (it may be in a folder labeled “Statistics” or “Software”)
- Double-click the SPSS 31 icon to launch the application
- SPSS may take a moment to load - be patient during the initial startup
I.20.4 Working with Files
- Opening Files: Use File → Open → Data to load SPSS data files (.sav)
- Importing Data: Use File → Import Data for Excel, CSV, or other formats
- Creating New Files: Start with a blank dataset using File → New → Data
I.20.5 Saving Your Work
Always save your work regularly! Apporto sessions may timeout, and unsaved work will be lost.
- Use File → Save As to save your SPSS data file (.sav)
- Save output files (.spv) separately using File → Export in the Output Viewer
- Files are typically saved to your personal network drive or OneDrive within Apporto
I.20.6 Downloading and Uploading Files
I.20.6.1 Uploading Files to Apporto
To transfer files from your local computer to Apporto:
- In the Apporto interface, the file manager opens to your Desktop by default
- Click the Upload button on the main top toolbar (it looks like an upward arrow)
- In the file picker dialog that opens, select the file(s) from your local computer
- Wait for the upload to complete - you’ll see a progress indicator
- Once uploaded, you can open the file in SPSS using File → Open → Data
I.20.6.2 Downloading Files from Apporto
To transfer files from Apporto to your local computer:
- In the Apporto interface, the file manager opens to your Desktop by default (where your files are typically saved)
- Select the SPSS data file (.sav) or output file (.spv) you want to download
- Click the Download button on the main top toolbar (it looks like a downward arrow)
- The file will be saved to your local computer’s Downloads folder
- You can then move the file to your preferred location on your computer
Keep your files organized by creating assignment-specific folders in Apporto. This makes it easier to find and manage your work.
I.20.7 Best Practices
- Browser Compatibility: Use Chrome, Firefox, or Edge for best performance
- Internet Connection: A stable internet connection is essential
- Session Timeouts: Apporto sessions may disconnect after periods of inactivity
- File Organization: Create folders for each assignment to keep your work organized
I.20.8 Troubleshooting
- SPSS Won’t Launch: Try refreshing your browser or restarting your Apporto session
- Slow Performance: Close unnecessary applications in Apporto
- File Access Issues: Ensure you’re saving to the correct location (usually your network drive)
- Connection Problems: Check your internet connection and try reconnecting to Apporto
If you encounter persistent issues, contact your instructor or IT support for assistance.
I.20.9 Additional Resources
- Apporto User Guide (available through your institution)
- SPSS Help: Press F1 within SPSS for context-sensitive help
- Course materials and video tutorials on SPSS usage