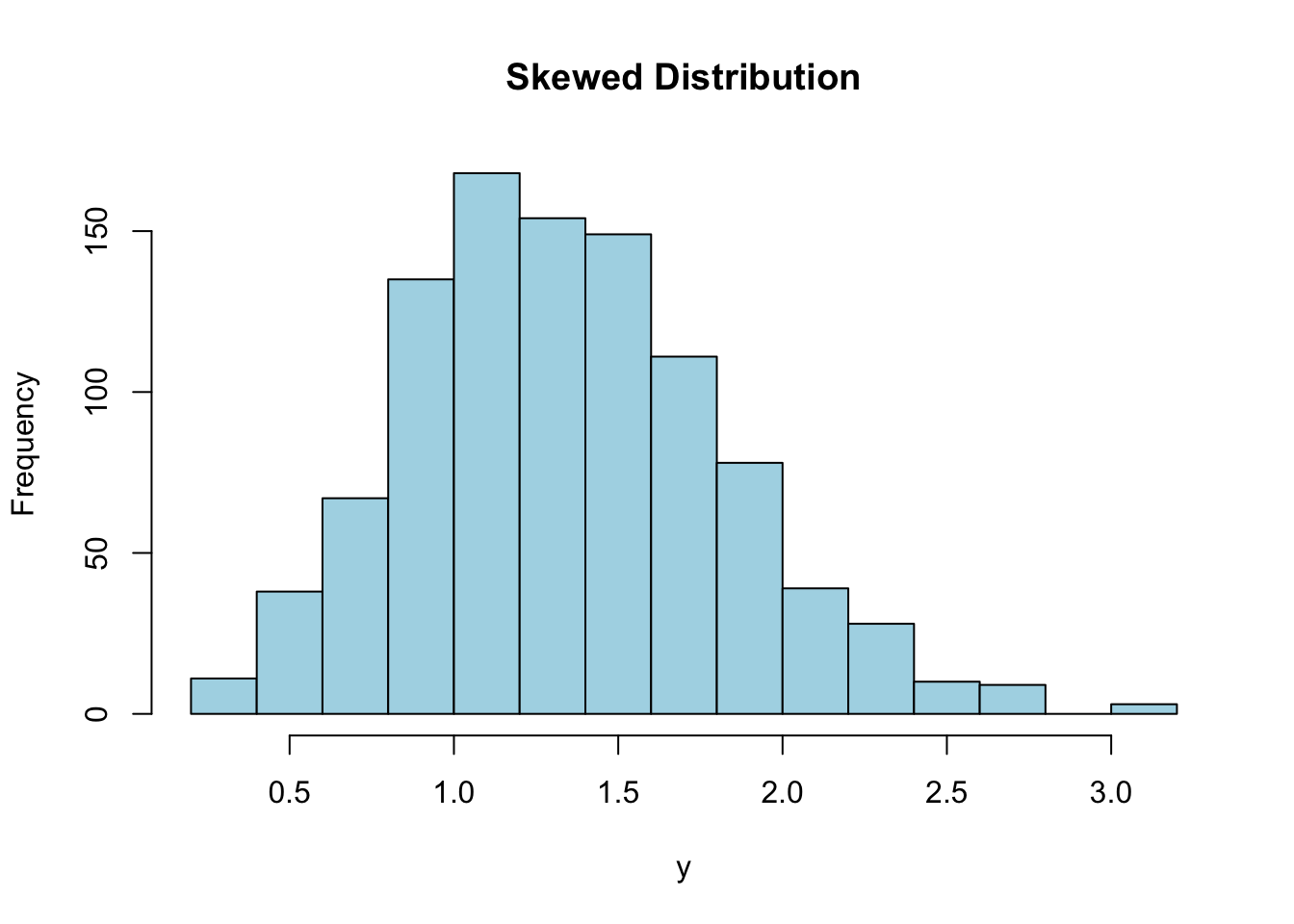
library(stats)
# Generate a gamma distributed random variable
x <- rgamma(n = 1000, shape = 2, rate = 1)
# Create a skewed distribution by taking the square root of the gamma variable
y <- sqrt(x)
# Plot the histogram of the skewed distribution
hist(y, breaks = 20, col = "lightblue", main = "Skewed Distribution")